某信号源符号集由字母A.B.C.D组成,若传输每一个字母用二进制[1]码元[2]编码,“00”代替A.“01”代替B,“10”代替C,“11”代替D,每个二进制码元宽度为5ms。(1)不同的字母是等可能出现时,试计算传输的平均信息速率:(2)若每个字母出现的可能性分别为_(A)=dfrac (1)(5) _(B)=dfrac (1)(4) _(C)=dfrac (1)(4) ._(D)=dfrac (3)(10)是计算传输的平均信息速率。
(1)不同的字母是等可能出现时,试计算传输的平均信息速率:
(2)若每个字母出现的可能性分别为
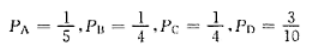
是计算传输的平均信息速率。
题目解答
答案
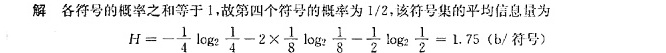
解析
考查要点:本题主要考查平均信息速率的计算,涉及香农公式和符号传输速率的理解。
解题思路:
- 平均信息量(香农公式):根据各符号出现的概率计算符号的平均信息量。
- 符号传输速率:根据码元宽度和每个符号占用的码元数,计算符号传输速率。
- 信息速率:将平均信息量与符号传输速率相乘得到最终结果。
关键点:
- 香农公式:$H = -\sum p_i \log_2 p_i$(单位:比特/符号)。
- 符号传输速率:码元速率 ÷ 每符号码元数。
- 信息速率:$R = H \times \text{符号传输速率}$(单位:比特/秒)。
第(1)题
条件:四个符号等概率,即 $p_A = p_B = p_C = p_D = \dfrac{1}{4}$。
计算平均信息量
$H = 4 \times \left( \dfrac{1}{4} \log_2 4 \right) = 4 \times \left( \dfrac{1}{4} \times 2 \right) = 2 \, \text{比特/符号}.$
计算符号传输速率
- 码元宽度为 $5 \, \text{ms}$,码元速率为 $\dfrac{1}{5 \times 10^{-3}} = 200 \, \text{码元/秒}$。
- 每符号占用 $2$ 个码元,符号速率为 $\dfrac{200}{2} = 100 \, \text{符号/秒}$。
计算信息速率
$R = H \times \text{符号速率} = 2 \times 100 = 200 \, \text{比特/秒}.$
第(2)题
条件:符号概率分别为 $p_A = \dfrac{1}{5}$,$p_B = \dfrac{1}{4}$,$p_C = \dfrac{1}{4}$,$p_D = \dfrac{3}{10}$。
计算平均信息量
$\begin{aligned}H &= -\left( \dfrac{1}{5} \log_2 \dfrac{1}{5} + \dfrac{1}{4} \log_2 \dfrac{1}{4} + \dfrac{1}{4} \log_2 \dfrac{1}{4} + \dfrac{3}{10} \log_2 \dfrac{3}{10} \right) \\&\approx -\left( 0.4644 + 0.5 + 0.5 + 0.5211 \right) \\&\approx 1.9855 \, \text{比特/符号}.\end{aligned}$
计算信息速率
符号速率仍为 $100 \, \text{符号/秒}$,因此:
$R = 1.9855 \times 100 \approx 198.55 \, \text{比特/秒}.$