题目
为了更好地了解某地的水质情况,科研人员采集了该地各监测点当天的水质数据。数据中包含了各监测点的水质类别、水温(℃)、pH、溶解氧(mg/L)、高锰酸盐指数(mg/L)。通过数字化学习[1],小申了解到水质类别从高到低分为1-5类,级别最高(质量最好)为1,级别最低(质量最差)为5。(1)采集的水质数据如表所示,小申使用Python的数据分析核心库pandas提供的方法进行数据整理。经检查确认,对于同一监测点出现多条记录的情况,视为重复记录,只需保留其中的第一条。若读取的数据存放在变量df中,以下方法中能够正确去重的是 ____ 。 监测点名称 水质类别 水温 pH 溶解氧 高锰酸盐指数 监测点1 4 24.8 7.25 4.77 5.16 监测点2 3 23.6 7.56 5.62 3.54 监测点3 5 24 6.99 2.45 4.75 …… …… …… …… …… …… 监测点9 4 25 7.33 4.16 5.84 监测点2 3 23.6 7.56 5.62 3.54 监测点10 3 24.1 7.27 5.18 4.35 监测点11 1 23.3 7.74 7.76 1.86 A.df.dropna(axis=1,how='any',inplace=True)B.df.dropna(axis=0,how='any',inplace=False)C.df.drop_duplicates(subset=['监测点名称'],keep='first',inplace=True)D.df.drop_duplicates(subset=['监测点名称'],keep='last',inplace=False)(2)小申把整理后的数据存储于“T4_2.csv”文件中。如图所示,他写程序对这些数据进行分析,在水质类别为3的记录中,找出水温的最大值。请将程序填写完整,可以点击图标进入开发环境,数据文件与程序位于同一文件夹目录,本题提供的环境仅用作算法验证。(3)小申根据如表所示的水质数据,编写程序绘制如图所示的各监测点水质类别和溶解氧分布可视化图形。小申编写的程序如图所示,请将程序填写完整,可以点击图标进入开发环境,数据文件与程序位于同一文件夹目录,本题提供的环境仅用作算法验证。 监测点名称 水质类别 水温 pH 溶解氧 高锰酸盐指数 监测点1 4 24.8 7.25 4.77 5.16 监测点2 3 23.6 7.56 5.62 3.54 …… (4)小申了解到水温、pH、溶解氧、高锰酸盐等指标都会影响水质类别,他选择了溶解氧进行重点分析。分析如图所示的“各监测点水质类别和溶解氧分布”可视化图形,说出溶解氧指数最高的监测点的水质类别为 ____ 。请学习数字化资源中的“地表水环境质量标准”,尝试归纳水质类别和溶解氧之间的相关关系 ____ 。(5)小申了解到水质类别符合1类标准需要从多个指标进行判断,其中要求溶解氧(mg/L)≥7.5。小申设计了一个算法,判断样本在溶解氧指标上是否符合1类标准。下面是小申设计的算法流程图,该流程图不满足算法特征的 ____ 。A.有穷性B.有一个或多个输出C.确定性D.有零个或多个输入(6)小申设计了一个算法,判断样本的水质类别是否符合2类及以上标准(即水质类别1-2认为符合,其他认为不符合)。小申编写的程序如图所示,以下选项填入划线处正确的是 ____ 。A.r<2B.r==1 and r==2C.r>=2D.r==1 or r==2(7)小申采集了某监测点的水质数据,部分数据如表所示。小申设计了一个算法,统计水质类别为1的天数。请选择合适的框图,将其拖至右侧流程图的虚线框内,将算法设计完整。 日期 水质类别 pH 溶解氧 高锰酸盐指数 2021/1/1 3 7.54 5.39 4.5 2021/1/2 3 7.47 6.42 4.85 2021/1/3 2 7.8 6.52 1.52 2021/1/4 1 6.5 8.24 1.36 2021/1/5 3 7.56 5.21 4.74 2021/1/6 2 7.27 7.08 1.03 2021/1/7 2 6.87 6.87 1.03 2021/1/8 2 6.59 6.59 1.94 2021/1/9 1 7.76 7.76 3.36 (8)小申编写程序统计某监测点水质类别为1的天数。请完善程序代码,将程序以原文件名保存在默认位置。点击图标进入开发环境。数据存储于T4_8.csv文件中,与该程序位于同一文件夹目录。
为了更好地了解某地的水质情况,科研人员采集了该地各监测点当天的水质数据。数据中包含了各监测点的水质类别、水温(℃)、pH、溶解氧(mg/L)、高锰酸盐指数(mg/L)。通过数字化学习[1],小申了解到水质类别从高到低分为1-5类,级别最高(质量最好)为1,级别最低(质量最差)为5。
(1)采集的水质数据如表所示,小申使用Python的数据分析核心库pandas提供的方法进行数据整理。经检查确认,对于同一监测点出现多条记录的情况,视为重复记录,只需保留其中的第一条。若读取的数据存放在变量df中,以下方法中能够正确去重的是 ____ 。
A.df.dropna(axis=1,how='any',inplace=True)
B.df.dropna(axis=0,how='any',inplace=False)
C.df.drop_duplicates(subset=['监测点名称'],keep='first',inplace=True)
D.df.drop_duplicates(subset=['监测点名称'],keep='last',inplace=False)
(2)小申把整理后的数据存储于“T4_2.csv”文件中。如图所示,他写程序对这些数据进行分析,在水质类别为3的记录中,找出水温的最大值。请将程序填写完整,可以点击图标 进入开发环境,数据文件与程序位于同一文件夹目录,本题提供的环境仅用作算法验证。
进入开发环境,数据文件与程序位于同一文件夹目录,本题提供的环境仅用作算法验证。

(3)小申根据如表所示的水质数据,编写程序绘制如图所示的各监测点水质类别和溶解氧分布可视化图形。小申编写的程序如图所示,请将程序填写完整,可以点击图标进入开发环境,数据文件与程序位于同一文件夹目录,本题提供的环境仅用作算法验证。
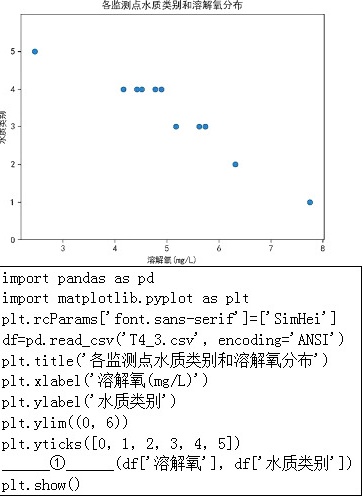
(4)小申了解到水温、pH、溶解氧、高锰酸盐等指标都会影响水质类别,他选择了溶解氧进行重点分析。分析如图所示的“各监测点水质类别和溶解氧分布”可视化图形,说出溶解氧指数最高的监测点的水质类别为 ____ 。请学习数字化资源中的“地表水环境质量标准”,尝试归纳水质类别和溶解氧之间的相关关系 ____ 。
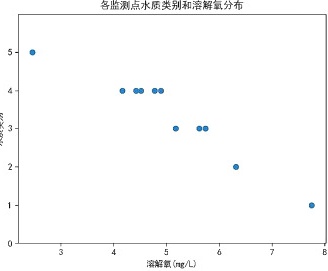
(5)小申了解到水质类别符合1类标准需要从多个指标进行判断,其中要求溶解氧(mg/L)≥7.5。小申设计了一个算法,判断样本在溶解氧指标上是否符合1类标准。下面是小申设计的算法流程图,该流程图不满足算法特征的 ____ 。
A.有穷性
B.有一个或多个输出
C.确定性
D.有零个或多个输入
(6)小申设计了一个算法,判断样本的水质类别是否符合2类及以上标准(即水质类别1-2认为符合,其他认为不符合)。小申编写的程序如图所示,以下选项填入划线处正确的是 ____ 。

A.r<2
B.r==1 and r==2
C.r>=2
D.r==1 or r==2
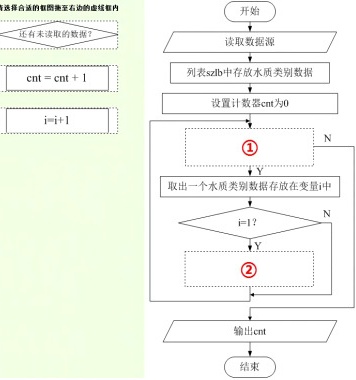
(7)小申采集了某监测点的水质数据,部分数据如表所示。小申设计了一个算法,统计水质类别为1的天数。请选择合适的框图,将其拖至右侧流程图的虚线框内,将算法设计完整。
(8)小申编写程序统计某监测点水质类别为1的天数。请完善程序代码,将程序以原文件名保存在默认位置。点击图标进入开发环境。数据存储于T4_8.csv文件中,与该程序位于同一文件夹目录。

(1)采集的水质数据如表所示,小申使用Python的数据分析核心库pandas提供的方法进行数据整理。经检查确认,对于同一监测点出现多条记录的情况,视为重复记录,只需保留其中的第一条。若读取的数据存放在变量df中,以下方法中能够正确去重的是 ____ 。
| 监测点名称 | 水质类别 | 水温 | pH | 溶解氧 | 高锰酸盐指数 |
| 监测点1 | 4 | 24.8 | 7.25 | 4.77 | 5.16 |
| 监测点2 | 3 | 23.6 | 7.56 | 5.62 | 3.54 |
| 监测点3 | 5 | 24 | 6.99 | 2.45 | 4.75 |
| …… | …… | …… | …… | …… | …… |
| 监测点9 | 4 | 25 | 7.33 | 4.16 | 5.84 |
| 监测点2 | 3 | 23.6 | 7.56 | 5.62 | 3.54 |
| 监测点10 | 3 | 24.1 | 7.27 | 5.18 | 4.35 |
| 监测点11 | 1 | 23.3 | 7.74 | 7.76 | 1.86 |
B.df.dropna(axis=0,how='any',inplace=False)
C.df.drop_duplicates(subset=['监测点名称'],keep='first',inplace=True)
D.df.drop_duplicates(subset=['监测点名称'],keep='last',inplace=False)
(2)小申把整理后的数据存储于“T4_2.csv”文件中。如图所示,他写程序对这些数据进行分析,在水质类别为3的记录中,找出水温的最大值。请将程序填写完整,可以点击图标
进入开发环境,数据文件与程序位于同一文件夹目录,本题提供的环境仅用作算法验证。(3)小申根据如表所示的水质数据,编写程序绘制如图所示的各监测点水质类别和溶解氧分布可视化图形。小申编写的程序如图所示,请将程序填写完整,可以点击图标
进入开发环境,数据文件与程序位于同一文件夹目录,本题提供的环境仅用作算法验证。| 监测点名称 | 水质类别 | 水温 | pH | 溶解氧 | 高锰酸盐指数 |
| 监测点1 | 4 | 24.8 | 7.25 | 4.77 | 5.16 |
| 监测点2 | 3 | 23.6 | 7.56 | 5.62 | 3.54 |
| …… |
(4)小申了解到水温、pH、溶解氧、高锰酸盐等指标都会影响水质类别,他选择了溶解氧进行重点分析。分析如图所示的“各监测点水质类别和溶解氧分布”可视化图形,说出溶解氧指数最高的监测点的水质类别为 ____ 。请学习数字化资源中的“地表水环境质量标准”,尝试归纳水质类别和溶解氧之间的相关关系 ____ 。
(5)小申了解到水质类别符合1类标准需要从多个指标进行判断,其中要求溶解氧(mg/L)≥7.5。小申设计了一个算法,判断样本在溶解氧指标上是否符合1类标准。下面是小申设计的算法流程图,该流程图不满足算法特征的 ____ 。
A.有穷性
B.有一个或多个输出
C.确定性
D.有零个或多个输入
(6)小申设计了一个算法,判断样本的水质类别是否符合2类及以上标准(即水质类别1-2认为符合,其他认为不符合)。小申编写的程序如图所示,以下选项填入划线处正确的是 ____ 。
A.r<2
B.r==1 and r==2
C.r>=2
D.r==1 or r==2
(7)小申采集了某监测点的水质数据,部分数据如表所示。小申设计了一个算法,统计水质类别为1的天数。请选择合适的框图,将其拖至右侧流程图的虚线框内,将算法设计完整。
| 日期 | 水质类别 | pH | 溶解氧 | 高锰酸盐指数 |
| 2021/1/1 | 3 | 7.54 | 5.39 | 4.5 |
| 2021/1/2 | 3 | 7.47 | 6.42 | 4.85 |
| 2021/1/3 | 2 | 7.8 | 6.52 | 1.52 |
| 2021/1/4 | 1 | 6.5 | 8.24 | 1.36 |
| 2021/1/5 | 3 | 7.56 | 5.21 | 4.74 |
| 2021/1/6 | 2 | 7.27 | 7.08 | 1.03 |
| 2021/1/7 | 2 | 6.87 | 6.87 | 1.03 |
| 2021/1/8 | 2 | 6.59 | 6.59 | 1.94 |
| 2021/1/9 | 1 | 7.76 | 7.76 | 3.36 |
(8)小申编写程序统计某监测点水质类别为1的天数。请完善程序代码,将程序以原文件名保存在默认位置。点击图标
进入开发环境。数据存储于T4_8.csv文件中,与该程序位于同一文件夹目录。题目解答
答案
解:(1)dropna是删除缺失值的列或行;drop_duplicates删除重复值,keep:确定要保留的重复值,first保留第一次出现的重复值。故本题应选C。
(2)水质类别从高到低分为1-5类,级别最高(质量最好)为1,级别最低(质量最差)为5。在水质类别为3的记录中,找出水温的最大值。因此划线处填df[“水质类别“]。
(3)由图中可知绘制的是散点图。故画线处代码为:plt.scatter。
(4)由图中可知溶解氧指数最高的监测点的水质类别为1。溶解氧越高,水质类别质量越好。
(5)确定性:算法中每一步的含义必须是确切的,不可出现任何二义性。判断框中:d>某数值,不满足算法确定性特征。故本题应选C。
(6)and是且,or是或,判断样本的水质类别是否符合2类及以上标准(即水质类别1-2认为符合,其他认为不符合),因此if判断条件是r==1 or r==2,故本题选D选项。
(7)依次读取水质类别数据,如果还有未读取的数据,则继续读取下一个数据,对读取的数据进行判断,如果水质类别为1,则计数cnt加1。故①为: ②为:
②为:
(8)统计某监测点水质类别为1的天数,依次对水质类别进行比较,如果水质类别为1,则计数加1。故代码如下:
for i in szlb:
if i==1:
cnt+=1
(2)水质类别从高到低分为1-5类,级别最高(质量最好)为1,级别最低(质量最差)为5。在水质类别为3的记录中,找出水温的最大值。因此划线处填df[“水质类别“]。
(3)由图中可知绘制的是散点图。故画线处代码为:plt.scatter。
(4)由图中可知溶解氧指数最高的监测点的水质类别为1。溶解氧越高,水质类别质量越好。
(5)确定性:算法中每一步的含义必须是确切的,不可出现任何二义性。判断框中:d>某数值,不满足算法确定性特征。故本题应选C。
(6)and是且,or是或,判断样本的水质类别是否符合2类及以上标准(即水质类别1-2认为符合,其他认为不符合),因此if判断条件是r==1 or r==2,故本题选D选项。
(7)依次读取水质类别数据,如果还有未读取的数据,则继续读取下一个数据,对读取的数据进行判断,如果水质类别为1,则计数cnt加1。故①为:
②为:(8)统计某监测点水质类别为1的天数,依次对水质类别进行比较,如果水质类别为1,则计数加1。故代码如下:
for i in szlb:
if i==1:
cnt+=1