题目
如图所示网络。A在t=0时刻开始向C发送一个2Mbits的文件;B在t=0.1+e秒(e为无限趋近于0的小正实数)向D发送一个1Mbits的文件。忽略传播延迟和结点[1]处理延迟。:10/s-|||-A 10 Mb/s C-|||-20Mb/s-|||-B D-|||-10 Mb/s 10 Mb/s请回答下列问题:如图所示网络。A在t=0时刻开始向C发送一个2Mbits的文件;B在t=0.1+e秒(e为无限趋近于0的小正实数)向D发送一个1Mbits的文件。忽略传播延迟和结点处理延如果图中网络采用存储-转发方式的分组交换,分组长度为等长的1kbits,且忽略分组头开销以及报文的拆装开销,则A将2Mbits的文件交付给C需要大约多长时间?B将1Mbits的文件交付给D需要大约多长时间?报文交换与分组交换相比,哪种交换方式更公平?(即传输数据量小用时少,传输数据量大用时长)
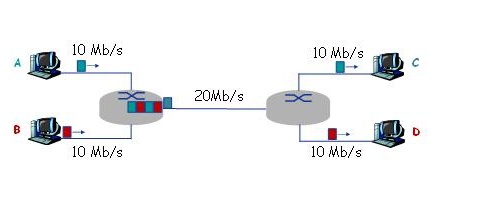
如图所示网络。A在t=0时刻开始向C发送一个2Mbits的文件;B在t=0.1+e秒(e为无限趋近于0的小正实数)向D发送一个1Mbits的文件。忽略传播延迟和结点[1]处理延迟。
请回答下列问题:
如图所示网络。A在t=0时刻开始向C发送一个2Mbits的文件;B在t=0.1+e秒(e为无限趋近于0的小正实数)向D发送一个1Mbits的文件。忽略传播延迟和结点处理延
如果图中网络采用存储-转发方式的分组交换,分组长度为等长的1kbits,且忽略分组头开销以及报文的拆装开销,则A将2Mbits的文件交付给C需要大约多长时间?B将1Mbits的文件交付给D需要大约多长时间?
报文交换与分组交换相比,哪种交换方式更公平?(即传输数据量小用时少,传输数据量大用时长)
请回答下列问题:
如图所示网络。A在t=0时刻开始向C发送一个2Mbits的文件;B在t=0.1+e秒(e为无限趋近于0的小正实数)向D发送一个1Mbits的文件。忽略传播延迟和结点处理延
如果图中网络采用存储-转发方式的分组交换,分组长度为等长的1kbits,且忽略分组头开销以及报文的拆装开销,则A将2Mbits的文件交付给C需要大约多长时间?B将1Mbits的文件交付给D需要大约多长时间?
报文交换与分组交换相比,哪种交换方式更公平?(即传输数据量小用时少,传输数据量大用时长)
题目解答
答案
参考答案:
由于A先发报文所以,A的报文在路由器的队列中排在B的报文前面,所以A交付2Mbits报文需要时间为:2/10+2/20+2/10=0.5s=500ms;
B将1Mbits的文件交付给D需要时间为:1/10+2/20(排队时间)+1/20+1/10=0.35s=350ms。
从t=0时刻到t=0.1s,A发送了1000个分组,用时:1000×1000/10000000=0.1s,
从t=0.1s时刻起与B共享连接路由器的链路[2],平均各共享到带宽10Mbps,A大约再用时:1/10+2×1000/10000000=0.1002s交付剩余的1000个分组,故A向C交付2Mbits文件大约需要(0.1+0.1002)s≈0.2s;
B向D交付1Mbits文件需要时间大约为:1/10+2×1000/10000000=0.1002s≈0.1s。
分组交换[3]比报文交换[4]更公平。
由于A先发报文所以,A的报文在路由器的队列中排在B的报文前面,所以A交付2Mbits报文需要时间为:2/10+2/20+2/10=0.5s=500ms;
B将1Mbits的文件交付给D需要时间为:1/10+2/20(排队时间)+1/20+1/10=0.35s=350ms。
从t=0时刻到t=0.1s,A发送了1000个分组,用时:1000×1000/10000000=0.1s,
从t=0.1s时刻起与B共享连接路由器的链路[2],平均各共享到带宽10Mbps,A大约再用时:1/10+2×1000/10000000=0.1002s交付剩余的1000个分组,故A向C交付2Mbits文件大约需要(0.1+0.1002)s≈0.2s;
B向D交付1Mbits文件需要时间大约为:1/10+2×1000/10000000=0.1002s≈0.1s。
分组交换[3]比报文交换[4]更公平。
解析
步骤 1:计算A发送2Mbits文件所需时间
A在t=0时刻开始向C发送一个2Mbits的文件。由于采用存储-转发方式的分组交换,分组长度为等长的1kbits,且忽略分组头开销以及报文的拆装开销,因此A发送2Mbits文件需要发送2000个分组。A发送第一个分组需要0.1秒,之后A和B共享连接路由器的链路,平均各共享到带宽10Mbps。因此,A发送剩余的1000个分组需要0.1002秒。所以,A将2Mbits的文件交付给C需要大约0.2秒。
步骤 2:计算B发送1Mbits文件所需时间
B在t=0.1+e秒(e为无限趋近于0的小正实数)向D发送一个1Mbits的文件。由于采用存储-转发方式的分组交换,分组长度为等长的1kbits,且忽略分组头开销以及报文的拆装开销,因此B发送1Mbits文件需要发送1000个分组。B发送第一个分组需要0.1秒,之后B和A共享连接路由器的链路,平均各共享到带宽10Mbps。因此,B发送剩余的1000个分组需要0.1002秒。所以,B将1Mbits的文件交付给D需要大约0.1秒。
步骤 3:比较报文交换与分组交换的公平性
报文交换与分组交换相比,分组交换更公平。因为分组交换将数据分割成多个小的分组进行传输,每个分组独立传输,可以更好地利用网络资源,减少传输延迟,提高网络的公平性。
A在t=0时刻开始向C发送一个2Mbits的文件。由于采用存储-转发方式的分组交换,分组长度为等长的1kbits,且忽略分组头开销以及报文的拆装开销,因此A发送2Mbits文件需要发送2000个分组。A发送第一个分组需要0.1秒,之后A和B共享连接路由器的链路,平均各共享到带宽10Mbps。因此,A发送剩余的1000个分组需要0.1002秒。所以,A将2Mbits的文件交付给C需要大约0.2秒。
步骤 2:计算B发送1Mbits文件所需时间
B在t=0.1+e秒(e为无限趋近于0的小正实数)向D发送一个1Mbits的文件。由于采用存储-转发方式的分组交换,分组长度为等长的1kbits,且忽略分组头开销以及报文的拆装开销,因此B发送1Mbits文件需要发送1000个分组。B发送第一个分组需要0.1秒,之后B和A共享连接路由器的链路,平均各共享到带宽10Mbps。因此,B发送剩余的1000个分组需要0.1002秒。所以,B将1Mbits的文件交付给D需要大约0.1秒。
步骤 3:比较报文交换与分组交换的公平性
报文交换与分组交换相比,分组交换更公平。因为分组交换将数据分割成多个小的分组进行传输,每个分组独立传输,可以更好地利用网络资源,减少传输延迟,提高网络的公平性。